
We know SuperPaste needs to be tested on children, but India has millions of school-going children! We can’t possibly give SuperPaste to every single one. That would take forever, cost too much, and if we use hundreds of people to collect data, we’ll make lots of mistakes (inter-observer variation).
This chapter is about Sampling, which is the clever way researchers choose a small group (Sample) that is exactly like the big group (Population) so we can get accurate answers quickly.
1. Defining Our World: Population and Sample
First, we must be clear about who we are studying.
- Study Population: This is the whole big group that we want the final results to apply to.
- Example: If we want to know if SuperPaste prevents Dental Caries in all school-going children in India, then the Study Population is all school-going children in India.
- Sample: This is the small group of children we actually select and study. They must be representative of the whole population (matching in age, sex, urban/rural balance, etc.).
| Medical Terminology | Simple Idea |
| Sampling Unit (BSU) | The basic thing we are picking. |
| Sampling Frame | The complete list of everything we could possibly pick. |
| Sampling Scheme | The specific method we use to choose the units from the list. |
Why Sampling is Better than Studying Everyone
Studying a large population can lead to inaccurate results because of huge non-sampling errors (human mistakes in collecting data). A smaller, well-chosen Sample gives us a more accurate result, and any error we do get (sampling error) can be mathematically measured.
2. How to Pick: Probability vs. Non-Probability Samples
The way we pick our sample is crucial. Only one way lets us draw valid, scientific conclusions.
| Feature | Non-Probability Sample | Probability Sample (The Scientific Way) |
| Selection Chance | The chance of being selected is not known. | Every unit has a known probability of being selected. |
| Bias | Highly likely to be biased (e.g., picking only easy-to-reach schools). | Removes the possibility of bias in subject selection. |
| Use | Used mainly for quick checks or to generate a hypothesis. | The only method that allows us to use statistical tests and draw valid conclusions about the whole population. |
3. The Probability Sampling Methods
Since we want a valid conclusion about SuperPaste, we must use a Probability Sampling method.
A. Simple Random Sampling
- Simple Idea: Like drawing names out of a hat. Every single unit on the list has an equal chance of being picked.
- How: You need a complete list (Sampling Frame) of all units, then you pick numbers randomly.
- Limitation: Requires a complete list, which is often hard to get for a huge population like India.
B. Systematic Sampling
- Simple Idea: Picking a starting point, then picking every k-th unit after that (e.g., every 10th child on a roster).
- Raw LaTeX Formula:
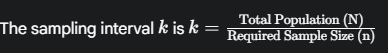
- Advantage: Very easy for our survey workers to implement (e.g., “Go to every 5th house”).
- Limitation: Can be tricky if the original list has a hidden order or cycle (e.g., if every 10th house is a big, rich house).
C. Stratified Sampling
- Simple Idea: We divide the whole population into layers or groups (strata) that are all similar within themselves, and then we pick samples from each layer.
- Example: Since we know boys and girls might have different dental habits, we create two strata: Male and Female. We pick a Simple Random Sample from the Male list and a Simple Random Sample from the Female list.
- Advantage: Ensures all important subgroups (like age groups, genders, or regions) are represented.
D. Cluster Sampling
- Simple Idea: We don’t list every individual child; we list groups or clusters (like schools or villages). We randomly pick a school (the cluster), and then we study all children in that selected school.
- Advantage: Less travel and fewer resources are needed because we stay in a few locations. We do not need a list of every single child in India, only a list of schools.
| Terminology | Unit Picked First | Unit Studied |
| Stratified Sampling | Individuals (from layers) | Individuals |
| Cluster Sampling | Groups (like Schools) | All individuals within the selected groups |
E. Multistage Sampling
- Simple Idea: Using a combination of the above methods in steps, often necessary for very large studies like ours.
- Example (Two-Stage): Stage 1 (Cluster): Randomly select 50 schools (clusters) across India. Stage 2 (Simple Random): Within those 50 selected schools, use the school roster as the Sampling Frame and randomly select 20 children from each school.
In conclusion, only by using Probability Samples can we ensure the results we get for SuperPaste are valid and can be trusted when applied to all the children in India!

Leave a Reply